






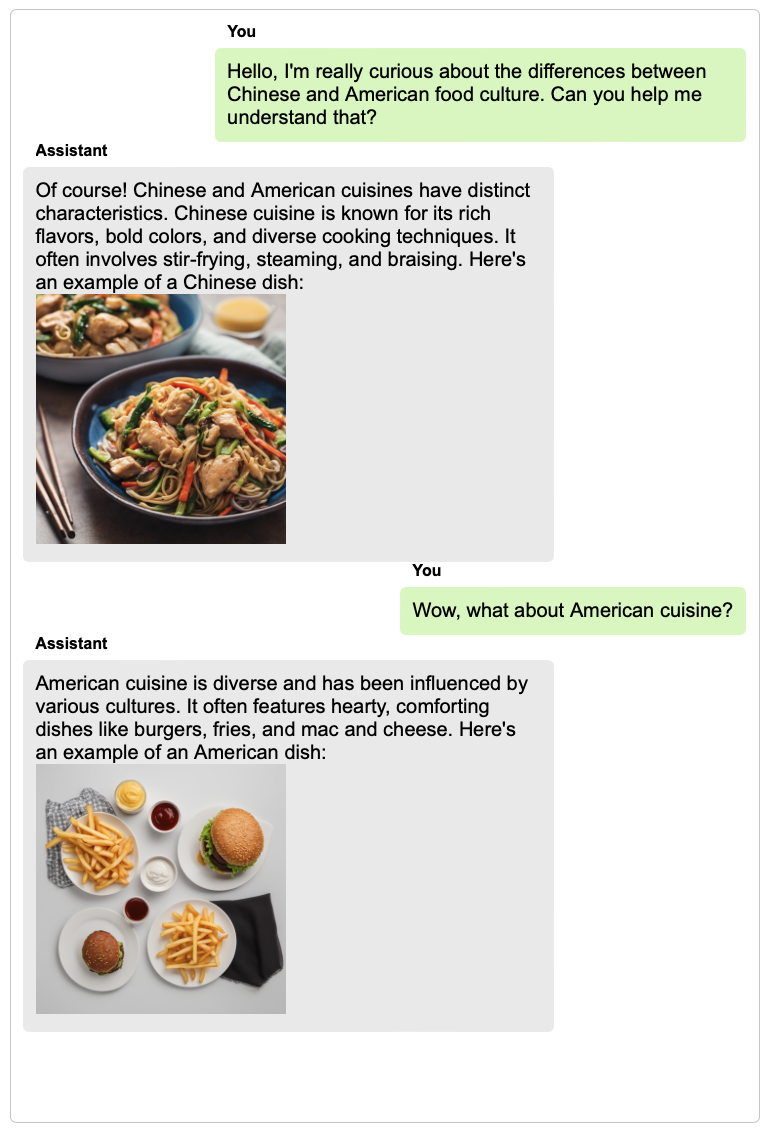
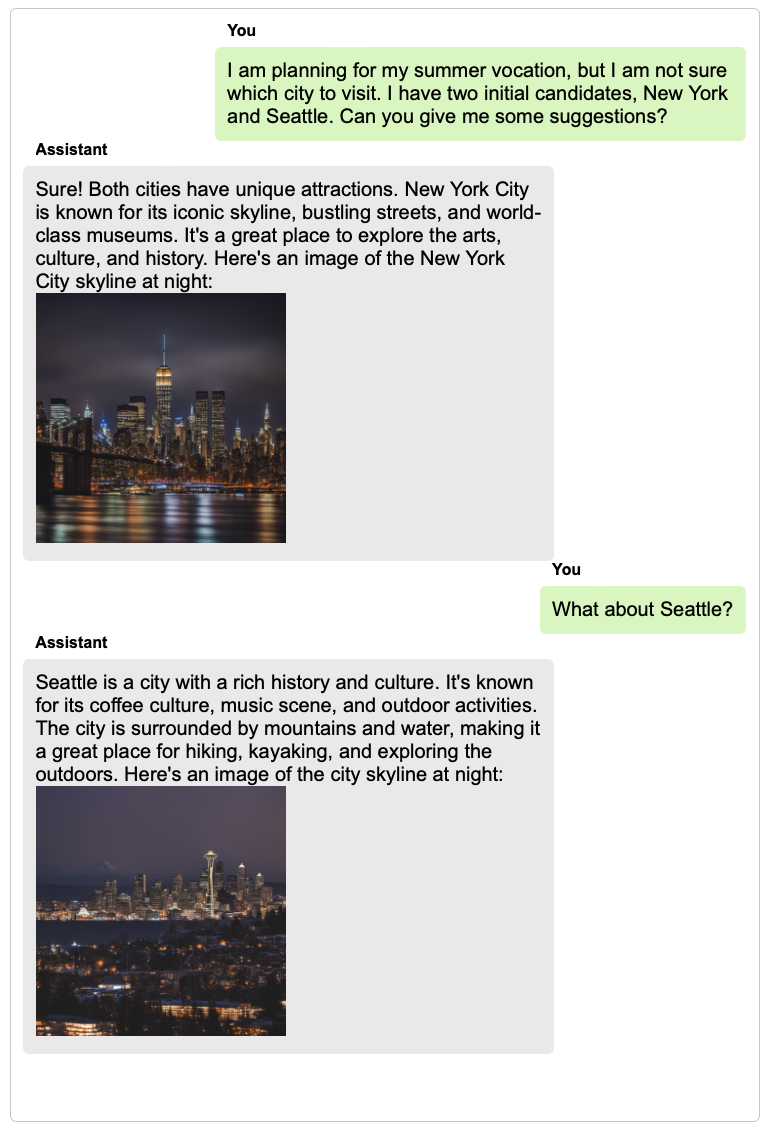
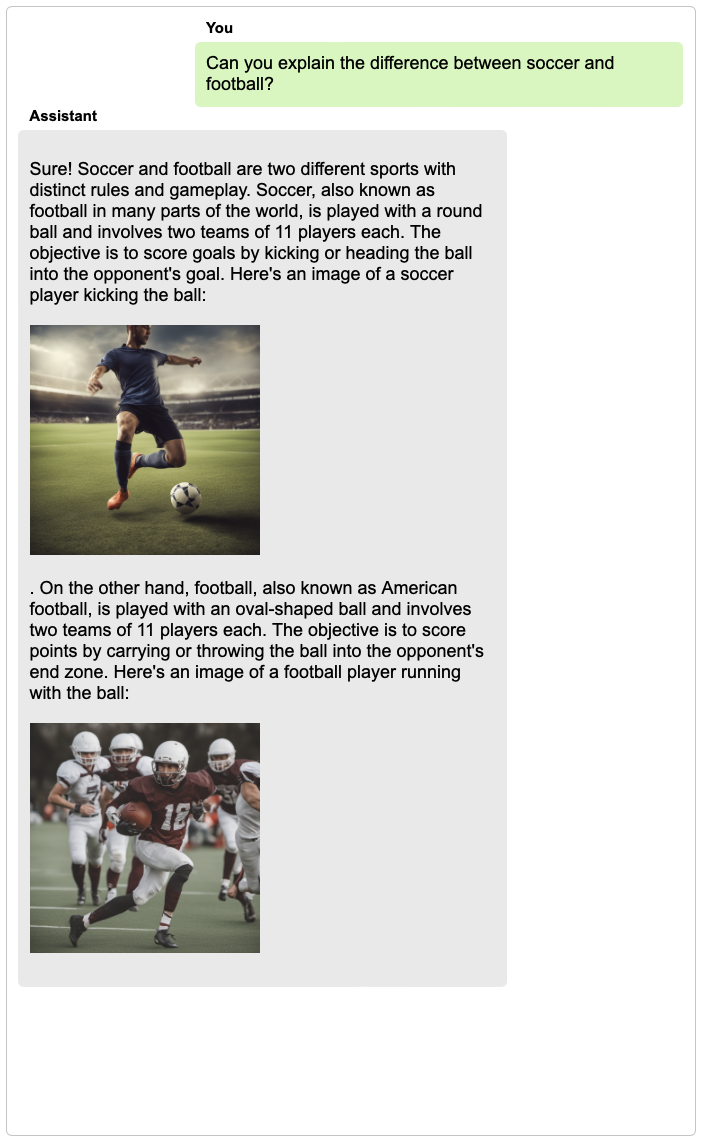
Large language models with instruction-following abilities have revolutionized the field of artificial intelligence. These models show exceptional generalizability to tackle various real-world tasks through their natural language interfaces. However, their performance heavily relies on high-quality exemplar data, which is often difficult to obtain. This challenge is further exacerbated when it comes to multimodal instruction following. We introduce TextBind, an almost annotation-free framework for empowering larger language models with the multi-turn interleaved multimodal instruction-following capabilities. Our approach requires only image-caption pairs and generates multi-turn multimodal instruction-response conversations from a language model. We release our dataset, model, and demo to foster future research in the area of multimodal instruction following.
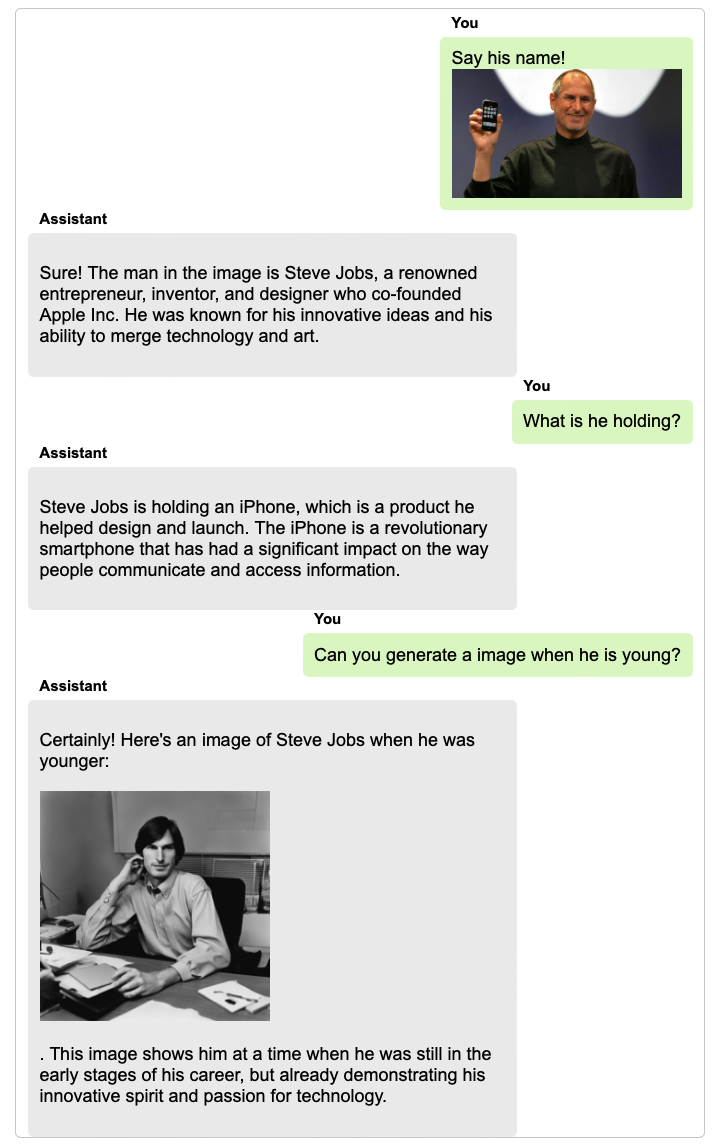
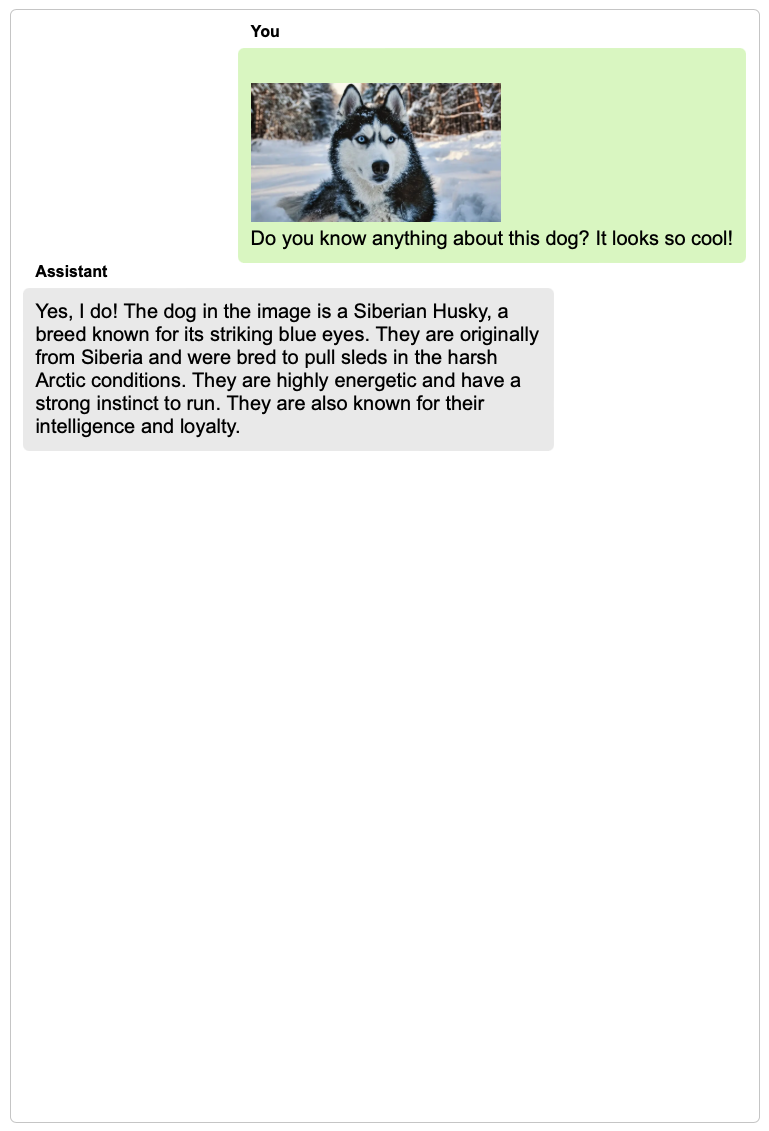
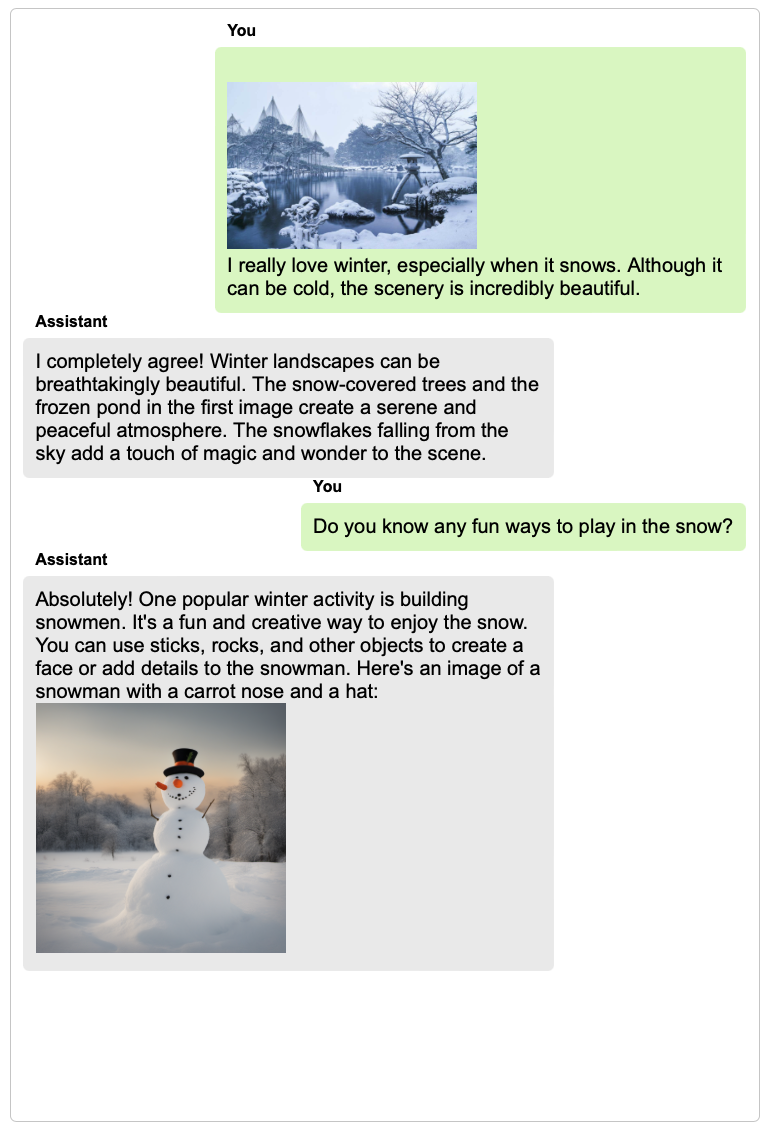
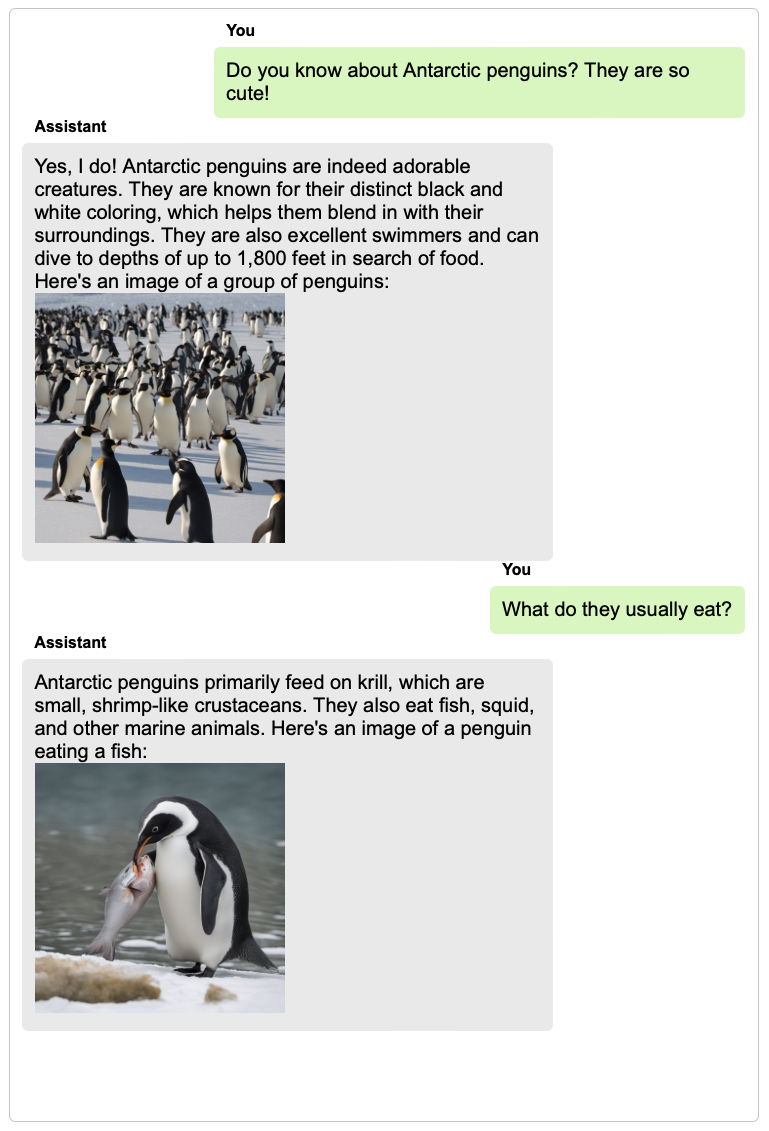
TextBind provides examples of processing and generating arbitrarily interleaved image-and-text content, enabling language models to naturally interact with users in open-world scenarios.
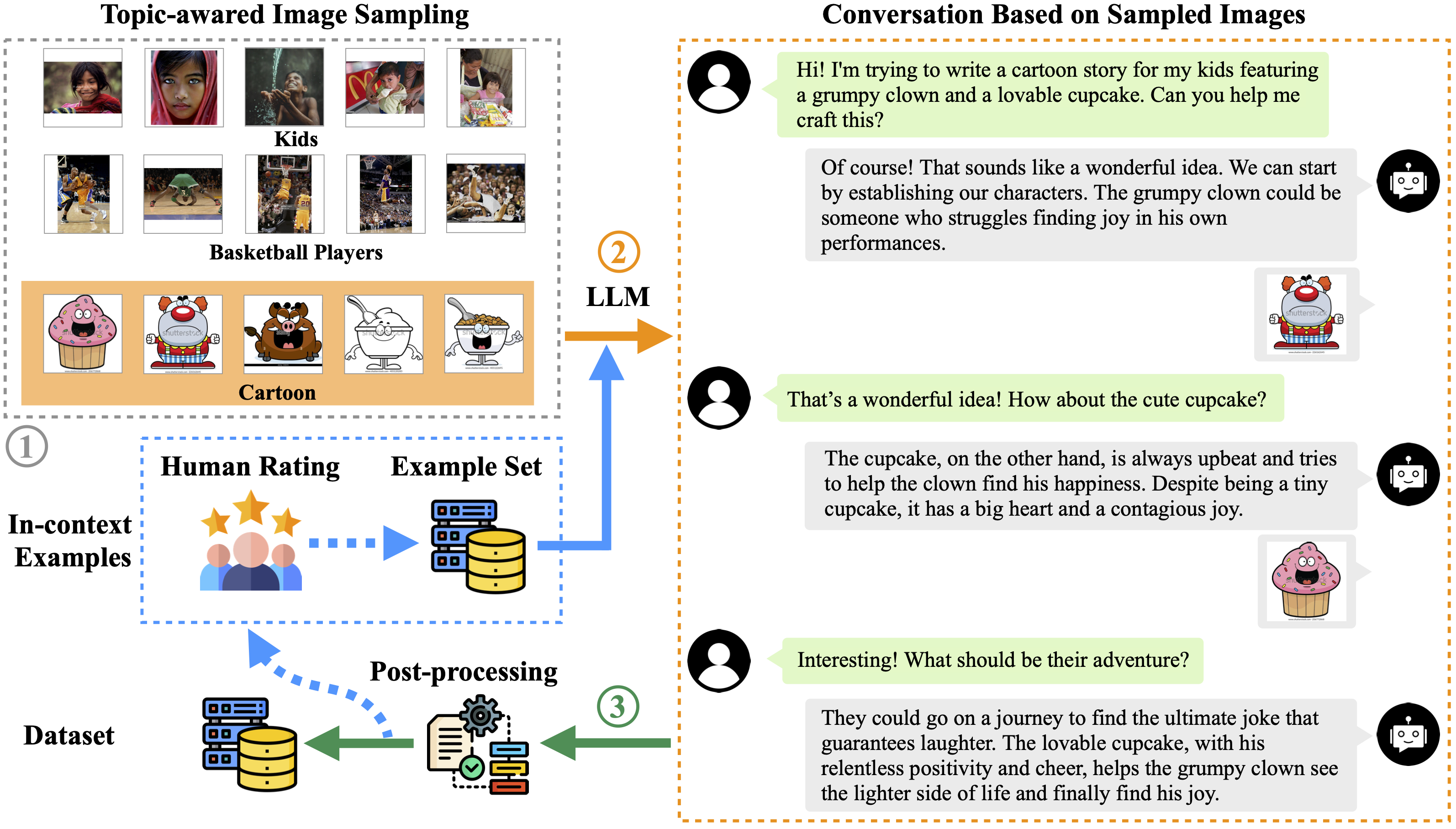
The data construction process of TextBind.
Our model consists of an image encoder, an image decoder, a language models, and bridging networks connecting all of them, supporting multi-turn interleaved multimodal instruction-following. It can generate process and generate arbitrarily interleaved image-and-text content.

The model architecture of TextBind.
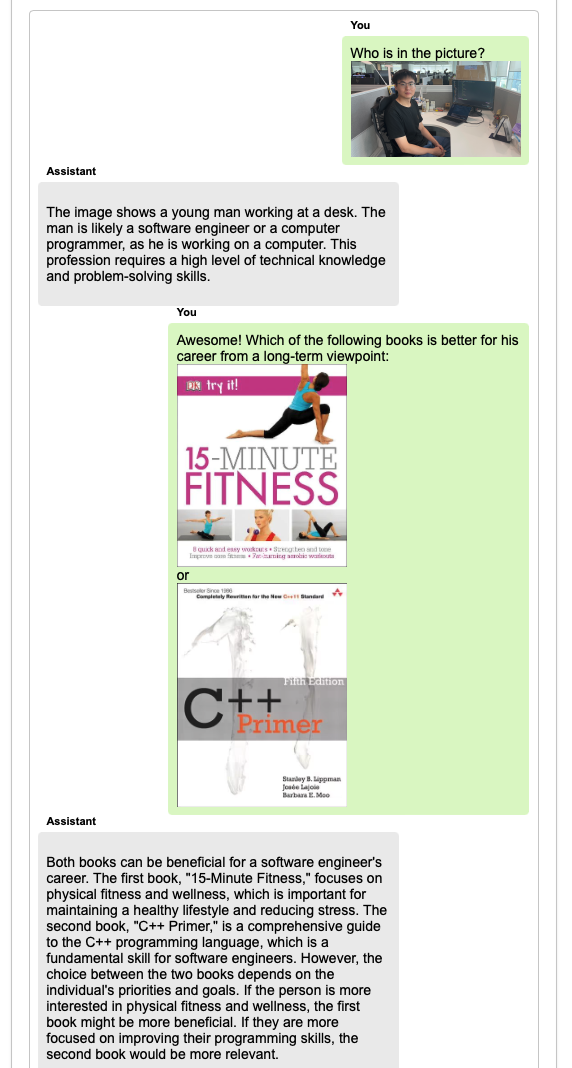
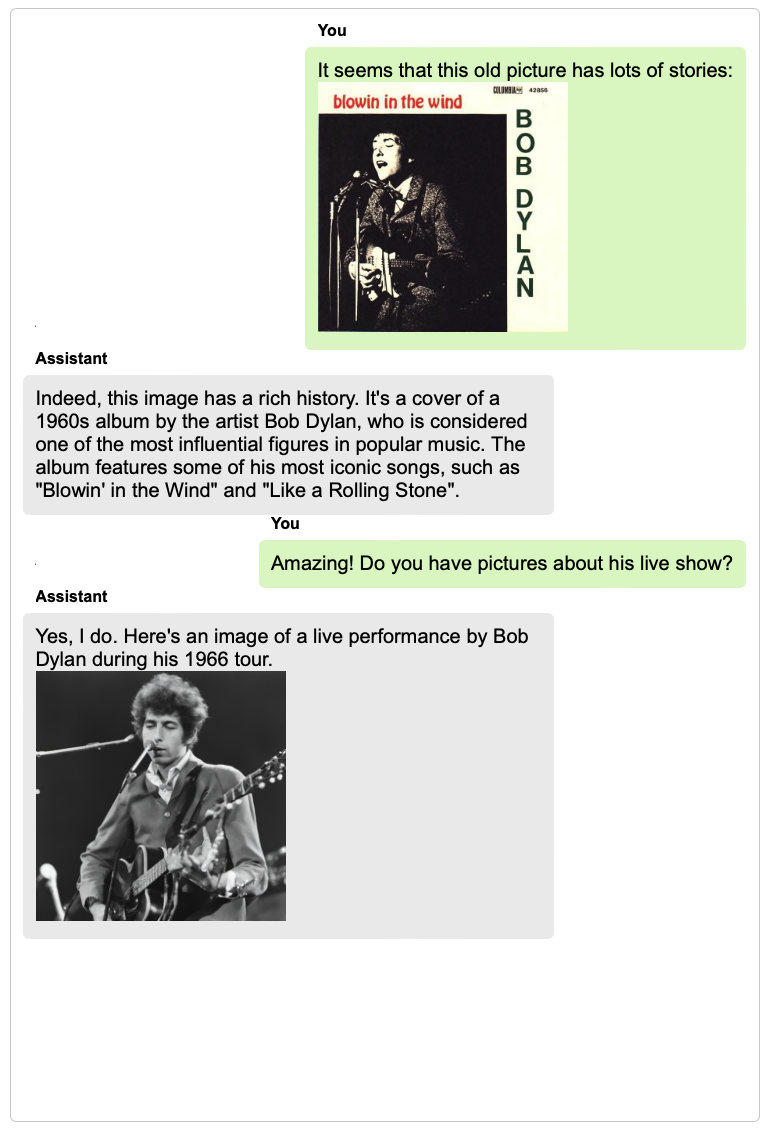
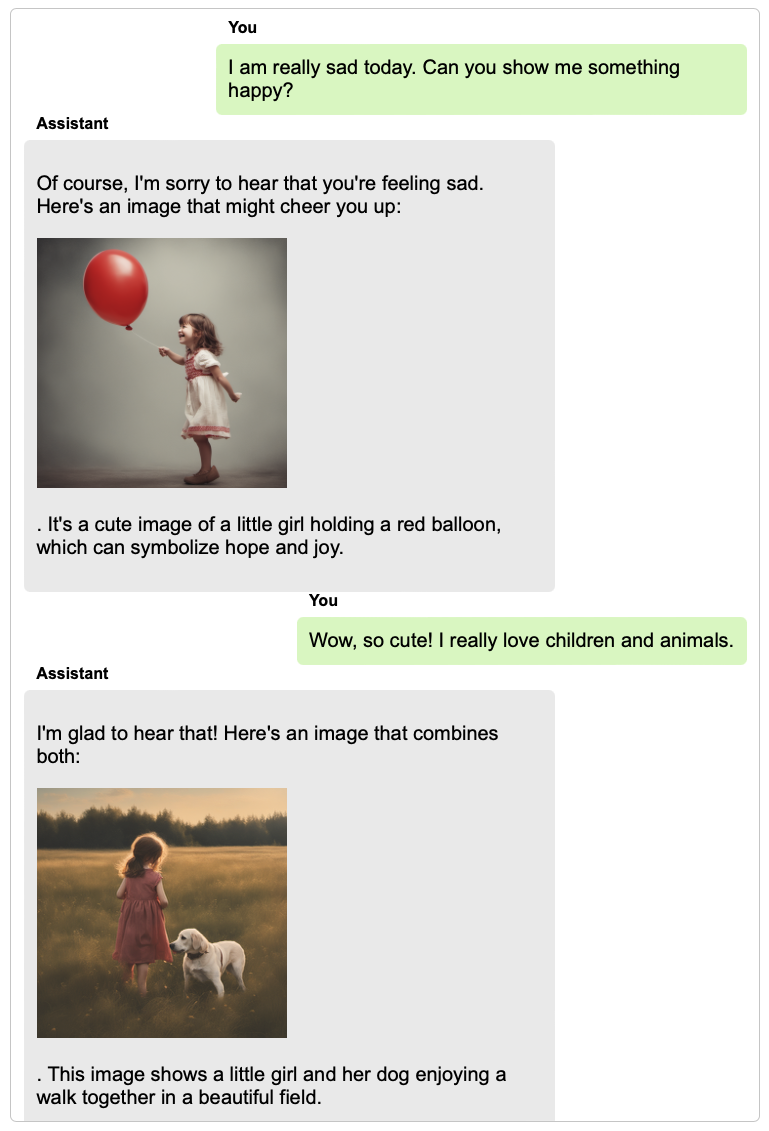
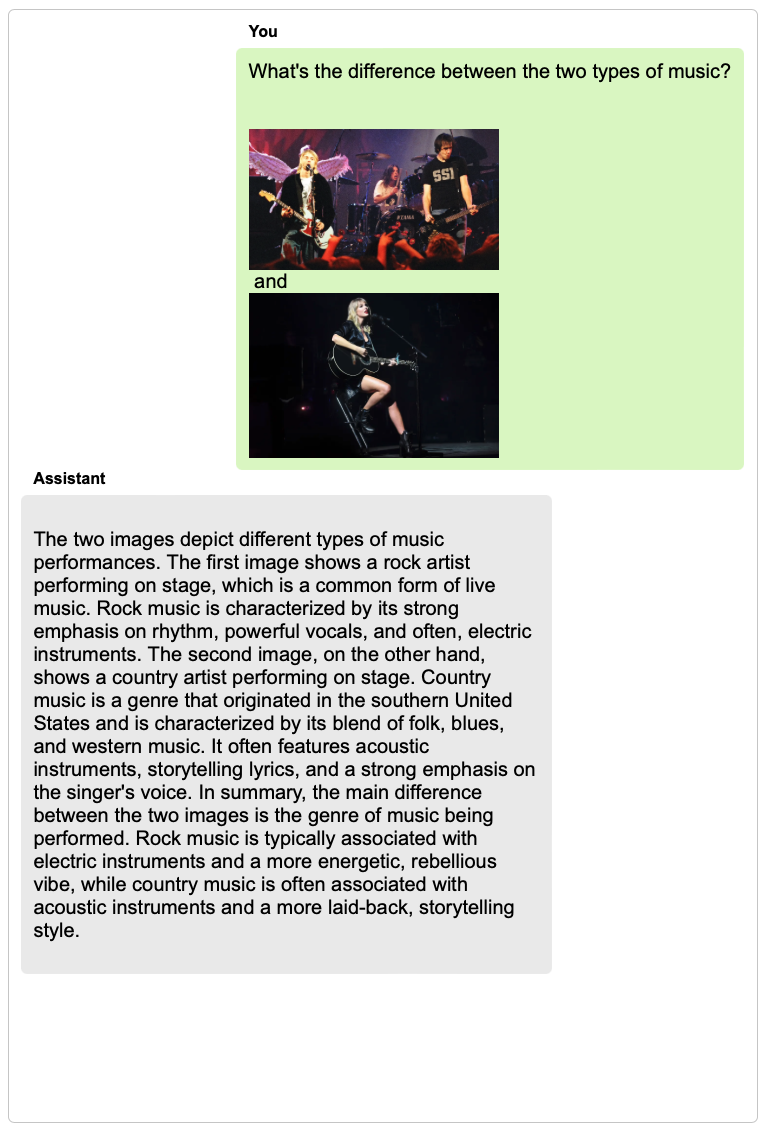
language models to perform a wide range of tasks, including composing engaging stories inspired by a set of images, comparing the common and different parts in multiple images, explaining concepts with vivid images, generating long coherent stories with illustrations, etc. Most interestingly, the core innovation of our model is its capability to naturally interact with users in broad real-world scenarios (with examples attached in the bottom of this page). Welcome to visit our demo.
@article{li2023textbind,
title={TextBind: Multi-turn Interleaved Multimodal Instruction-following in the Wild},
author={Li, Huayang and Li, Siheng and Cai, Deng and Wang, Longyue and Liu, Lemao and Watanabe, Taro and Yang, Yujiu and Shi, Shuming},
year={2023}
}
This website template is borrowed from the PandaGPT project, which is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.